Le fichier robots.txt est présent à la racine d'un site internet. Il permet aux robots d'exploration automatique du web d'indexer les sites, les pages, les images et les médias dans l'annuaire des différents moteurs de recherche ou autres services web. Ce fichier joue un rôle important et il est indispensable afin d'optimiser le référencement naturel d'un site. Il participe donc au SEO (Search Engine Optimization) qui se traduit par : optimisation pour les moteurs de recherche.
En effet, les robots d'exploration automatique ou robots d'indexation sont nombreux à parcourir la toile nuit et jour, 24h/24h. On les connaît plus couramment sous les termes anglais de "crawlers", "bots" ou encore "spiders". Ils n'ont qu'un seul et unique but, scanner le web en permanence afin de dénicher les contenus accessibles et alimenter ou mettre à jour les données du service dont ils dépendent. C'est cela qui permet aux moteurs de recherche de fournir des résultats pertinents et bien actualisés.

Le plus connus d'entre-eux : Googlebot appartient vous l'aurez compris à l'hégémonique géant de Montain View : Google. Mais il côtoie également Bingbot et MSNBot (appartenant respectivement à Bing et MSN Search de Microsoft) ou encore Slurp (Yahoo search), AppleBot (Apple Siri) et des dizaines d'autres encore, dont certains peuvent parfois même être des robots malveillants.
C'est là qu'entre en jeu le fichier robots.txt. En effet, c'est lui qui va vous permettre de donner des instructions à tous ces espions du web. Ainsi, vous pourrez leur autoriser ou interdire l'indexation de votre site internet et même leur en dissimuler certaines parties.
Étudions donc ce fichier robots.txt dans le détail et les bonnes pratiques à suivre le concernant :
- Tout d'abord, vous devez savoir que ce fichier est sensible à la casse. Pour fonctionner, il doit toujours être au format texte et nommé robots.txt, tout en minuscules au pluriel (attention donc à ne pas oublier le "s" à la fin). Il doit être encodé en UTF8 standard (sans BOM). Pour créer et enregistrer ce fichier il est donc fortement recommandé de na pas utiliser un logiciel de traitement de texte mais plutôt un éditeur de code tel que Notepad ++.
- De plus, il doit toujours être positionné à la racine de l'arborescence du site internet. Par exemple, si vous avez plusieurs sites internet (ou domaines) présents sur le même hébergement, il vous faudra un fichier robots.txt à la racine de chaque site (domaine). Un fichier robots.txt positionné dans un sous-répertoire sera ignoré des spiders.
- Mais encore, pour être fonctionnel et compris par les spiders votre fichier robots.txt ne doit contenir qu'une instruction par ligne et il est fortement conseillé de le limiter à une taille maximale de 500 ko. Par exemple GoogleBot ignorera les directives renseignées au delà de cette taille. Vous pouvez utiliser des lignes vides pour la lisibilité.
- Enfin, notez qu'il n'existe que 8 instructions (commandes et directives) comprises par les robots d'indexation du web :
User-agent qui permet d'instruire un robot particulier ou tous les robots
Allow: qui permet d'autoriser l'accès au contenu du site
Disallow: qui permet d'interdire l'accès. (Attention : Si Disallow: n'est suivit d'aucune commande, tout le contenu du site peut être exploré. Mais, avec un "/" simple ( Disallow: / ) alors tout le contenu du site est interdit.
Sitemap: qui permet de fournir l'adresse du sitemap aux robots.
Crawl-delay: une directive comprise par certains robots d'indexation, qui sert à limiter les requêtes d'exploration afin de ne pas surcharger le serveur web. (Utile pour les sites à forte affluence).
$ le dollar utilisé pour signifier la fin d'une URL
* le wildcard utilisé pour signifier "tous les"
# le dièse utilisé pour commenter une ligne
Étudions un exemple de fichier robots.txt :
# Autorisation de tous les robots
User-agent: *
# Limitation des requêtes
Crawl-delay: 30
# Répertoires interdits
Disallow: /wp-admin
Disallow: /wp-plugins
Disallow: /backup
# Fichiers autorisés
Allow: /*.css$
# Fichiers interdits
Disallow: /*.zip$
# Adresse du sitemap
Sitemap: http://www.adressedevotresite.fr/sitemap.xml
Dans l'exemple ci-dessus, User-agent: * signifie que tous les robots d'indexation sont autorisés à explorer le site internet. Crawl-delay: 30 leur impose un intervalle de trente secondes entre les requêtes d'exploration des pages.
Les trois lignes suivantes utilisent la commande Disallow: afin d'interdire l'exploration et l'indexation les répertoires / wp-admin , /wp-plugins et /backup. La ligne Allow: autorise l'indexation de tous les fichiers .css. La ligne Disallow: qui suit interdit l'indexation de tous les fichiers .zip.
Vous noterez que pour structurer le fichier robots.txt vous pouvez vous aider avec des lignes de commentaires précédées de # .
La ligne avec l'instruction Simetap: vous permet de fournir aux crawlers l'adresse du plan de votre site. Ce n'est pas une obligation, notamment si vous utilisez une plugin dédié, mais la pratique est courante. La convention veut que cette directive soit toujours la dernière du fichier. C'est un plus non négligeable qui participe au référencement naturel d'un site.
Si vous désirez interdire l'accès de votre site à des spiders spécifiques, il est recommandé de placer ces directives en début fichier avant l'autorisation des autres robots comme dans l'exemple ci-dessous :
# Robots interdits
User-agent: baiduspider
Disallow: /
User-agent: YandexBot
Disallow: /
User-agent: AppleBot
Disallow: /
# Robots autorisés
User-agent: *
Crawl-delay: 30
On peut voir ci-dessus qu'avec Disallow: / l'ensemble du site est interdit d'indexation aux robots d'exploration de Baidu, Yandex et Apple. Tous les autres robots sont ensuite autorisés à indexer le site avec User-agent: *
Si votre site est en cour de développement, que vous ne souhaitez pas qu'il soit référencé dans les moteurs avant sa finalisation ou que vous désirez tout simplement le garder privé et confidentiel, vous devez y placer à la racine le fichier robot.txt suivant dès sa mise en ligne afin d'en interdire l'accès à tous les spiders du web.
User-agent: *
Disallow: /
Si aucun fichier robots.txt ne figure à la racine de votre site, tous les robots d'indexation du web auront accès à la totalité des ressources mises en ligne.
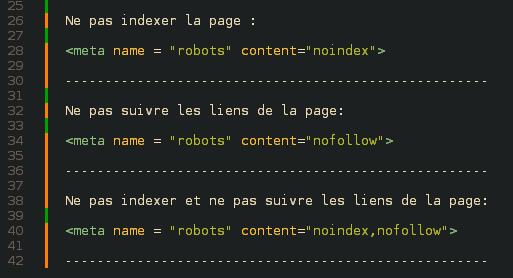
Pour ce qui concerne les pages d'un site, sachez que si vous désirez interdire l'indexation ou le suivi des liens de certaines il vaut mieux utiliser la méta-balise HTML Nofollow et Noindex directement au sein du code source des pages concernées. C'est une fonction largement implémentée dans les CMS actuels, et surtout, cela permet d'alléger le fichier robots.txt et vous assure une efficacité à 100%. Exemples ci-après:
Vous l'aurez compris, avoir un fichier robot.txt bien renseigné va vous permettre d'avoir des contenus référencés de manière pertinente et à jour au sein des moteurs de recherche de votre choix. Cela vous permettra également de les bloquer et d'interdire l'accès à certaines parties ou fichiers spécifiques de votre site qui n'aident pas au référencement ou doivent rester privés.
Bon référencement à toutes et tous. A bientôt.😉